5 Lessons to Learn from the Global Facebook, Instagram, and WhatsApp Outage
October 21, 2021
By Leigh Dow
If you restarted your Wi-Fi and phone more than once on October 4, 2021 – just to see Facebook, Instagram, and WhatsApp again not loading – you were in good company. Facebook, WhatsApp, and Instagram faced a major outage that lasted for at least five hours, leaving
3.51 billion monthly users in the dark.
The outage prevented people from connecting with their family, friends, and customers. It caused inconvenience for daily users, and numerous brands felt a negative impact on their businesses. The event also led social media users, such as influencers and brands, to reflect on what the Facebook outage meant for their futures.
Why did this outage happen and what does it teach us? We explore the answers below.
Facebook, Instagram, and WhatsApp Outage: What Went Wrong?
Facebook, Instagram, and WhatsApp all went offline at 11:45 AM ET on Monday, October 4 for users globally. Even the company’s internal communications tools went offline, slowing its ability to respond.
“Devs can’t access their apps online to push new builds, no documentation, nothing. All Oculus platform services are down. No avatars as well,” a developer whose work includes Facebook platforms told
Business Insider.
Amidst the outage, Facebook announced it was experiencing networking issues and gave no timeline for a fix. The company stated,
“Sincere apologies to everyone impacted by outages of Facebook-powered services right now. We are experiencing networking issues and teams are working as fast as possible to debug and restore as fast as possible.”
According to
Facebook’s statement regarding the outage, their engineering teams learned configuration changes on the backbone routers tasked with coordinating network traffic between their data centers caused issues interrupting the communication. This disruption to network traffic provided a cascading effect on the way their data centers communicate, bringing their services to a halt.
“The underlying cause of this outage also impacted many of the internal tools and systems we use in our day-to-day operations, complicating our attempts to quickly diagnose and resolve the problem,” the company reported.
Despite the many theories circling the internet since the outage, Facebook said it found no evidence of any compromised user information during the disruption. Once the service was restored, the company announced,
“Our services are now back online and we’re actively working to fully return them to regular operations. We want to make clear at this time we believe the root cause of this outage was a faulty configuration change. We also have no evidence that user data was compromised as a result of this downtime.”
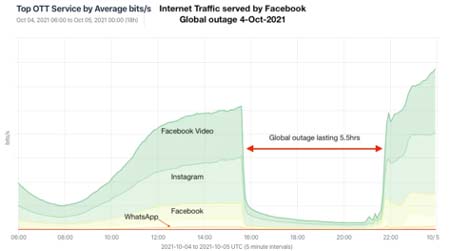
The Aftereffects of the Outage
First, the chain reaction the outage created was a major nuisance for Facebook’s employees, since much of their IT system depends on the parent company, Facebook.
According to Alex Hern, an editor at The Guardian,
“If the company accidentally cut its servers off from the internet, that would have also impaired its ability to update the internet with correct information, log in to Facebook’s systems to send that update, use a digital badge to access the server room where Facebook’s systems are housed, and send messages to the security team asking them to unlock the doors with a physical key.”
Facebook’s services also power a significant share of the digital economy. This means companies running Facebook and Instagram ads and communicating with customers on these platforms were also affected by the outage.
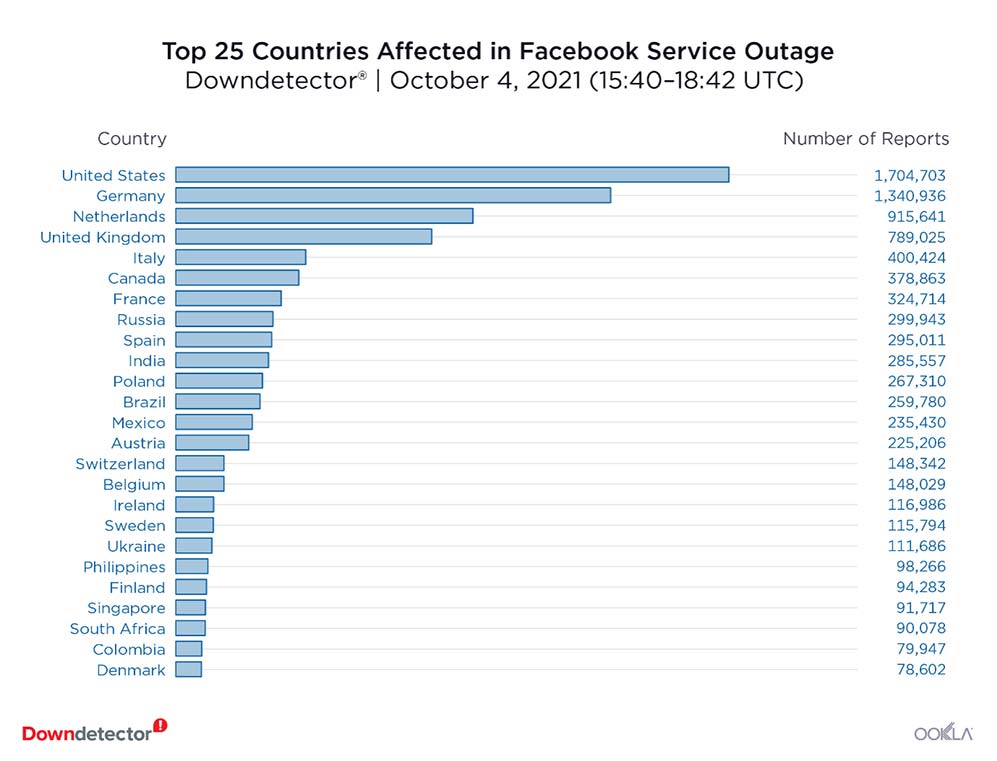
In many parts of the world, WhatsApp is the most popular messaging app and is used extensively for personal, professional, and political communication. This means Facebook’s outage also interrupted the ability of users in those areas to communicate with one another.
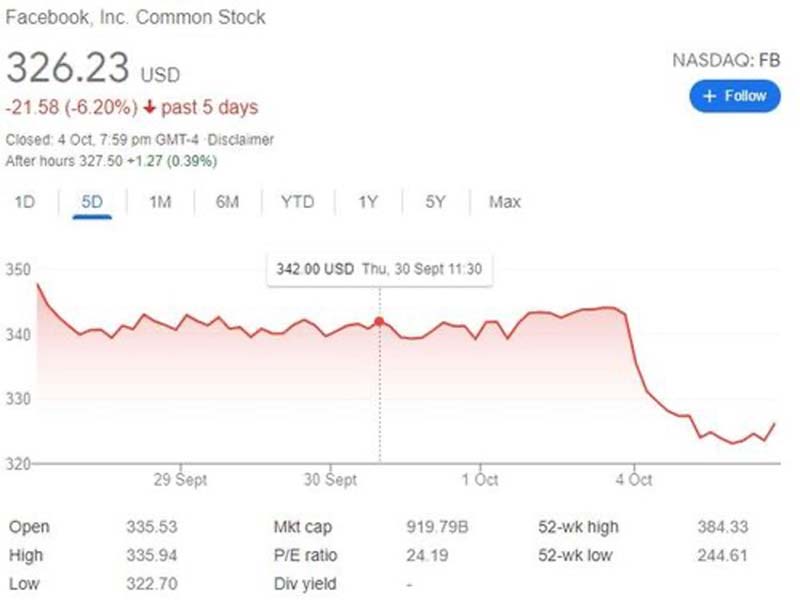
For Facebook’s CEO Mark Zuckerberg and other stakeholders in the company, it was a rough day. Zuckerberg’s net worth dropped by
$7 billion on October 4 as Facebook's stock declined by about 5%.
What Lessons Do We Learn from the Great Facebook Outage?
Our increasing reliance on these social media apps shows how the world is turning “phygital” – blurring the lines between our physical and digital lives. From marketing to consumer experience, even companies are using the concept of phygital to create smart strategies, trying to bring the best of e-commerce and brick-and-mortar retail together.
This incident also teaches us the importance of the Internet of Everything (IoE) concept, which according to
Cisco, is the networked connection of people, processes, data, and things. The biggest advantage of IoE is derived from the compound impact of connecting people, processes, data, and things, and the value this increased connectedness creates as “everything” comes online.
Phygital and IoE together are creating unprecedented opportunities for organizations, individuals, communities, and countries to realize dramatically greater value from networked connections among people, processes, data, and things.
This recent outage is a wake-up call for organizations to look within and make sure they have created the right technical and cultural atmosphere to prevent or mitigate a Facebook-like disaster. Here are five key steps for every business to consider:
1. Acknowledge human errors and build process to counteract them
Surprisingly, many of the IT catastrophes start with a simple error.
Per the Facebook infrastructure VP,
Santosh Janardhan, engineers were carrying out routine network maintenance when
“a command was issued with the intention to assess the availability of global backbone capacity, which unintentionally took down all the connections in our backbone network, effectively disconnecting Facebook data centers globally.”
This reminds us of the Amazon Web Services (AWS) outage in
February 2017, debilitating a number of websites for several hours. According to Amazon, one of its workers was debugging an issue with the billing system and accidentally took more servers offline than planned. This led to cascading failure of yet more systems. Human error also contributed to a preceding huge AWS outage in April 2011.
Each of these outages teach us an important lesson: Businesses must not imagine if they just try harder, they can stop humans from making errors. The truth is, with hundreds of employees manually entering thousands of commands daily, it is only a matter of time before someone makes a catastrophic mistake. As an alternative, businesses must inspect why an apparently small blunder in a command line can cause such extensive damage.
The underlying software should be capable of naturally limiting the negative impact of any individual command. According to Janardhan,
“Facebook had such a control; however, a bug in that audit tool prevented it from properly stopping the command.” Companies need to be diligent in checking these capabilities are working as envisioned.
Companies should also leverage automation technologies to decrease the amount of repetitive, often monotonous manual processes where so many blunders happen. This also requires circuit breakers for automations to avoid repairs from spiraling out of control and giving rise to yet more complications. We cannot forget how
Slack’s outage in January 2021 showed how automations can also cause cascading catastrophes.
2. Understand that tech is not perfect
It can be so easy to overlook the truth: Technology is not yet at a place of perfection (and might never be). There will always be a lot of room for innovation and growth. Even though tech is mostly dependable, it is vital to bear in mind things do not always happen as planned.
It is enticing to go and create new social media accounts on other platforms, like LinkedIn or TikTok in case of another outage, but is that the way to go? Unless you plan on being active on all existing platforms, having a dead or unused account will not reflect well on your brand. Trying to build a loyal following on a social platform \ your target audience is not on does not make sense.
For example, if you are a highly visual brand focusing on beautiful images, then you know Instagram is the place to be. A highly visual brand of images may not do well on LinkedIn.
3. Carry out investigations without pointing fingers
The next day after the incident, Mark Zuckerberg wrote,
“We’ve spent the past 24 hours debriefing on how we can strengthen our systems against this kind of failure.” This is significant, but it also highlights a critical point: Businesses suffering an outage should never blame individuals. Instead, they might consider the bigger picture of what systems and processes could have led to it.
Trying or working harder does not solve problems alone. You need to fix the core system. Businesses need to understand no individual wakes up in the morning planning to make an error, they simply happen. How can you prepare for the inevitable? Focus on the technical and administrative ways to decrease mistakes. See what lessons you can learn from every incident and then implement them to correct your processes and systems.
4. Avoid the deadlock of interdependent systems
Many companies face failures because of the deadlock occurring when too many systems in a network are mutually dependent. As a result, when one breaks, the other also nose-dives. This was another major factor in Facebook’s outage. The single flawed command sparked a domino effect shutting down the backbone connecting all the company’s data centers worldwide.
There was also problem with Facebook’s DNS servers translating human-readable hostnames to numeric IP addresses and according to Janardhan,
“it broke many of the internal tools we’d normally use to investigate and resolve outages like this.”
If you maintain a deep understanding of dependencies in a network, you will not be clueless when an outage or incident occurs. Redundancies and fallbacks in place will allow efforts to resolve an outage to proceed quickly. Your approach should be like how natural disasters are handled. If a calamity takes down the modern communication systems of first responders, they can still turn to older technologies such as ham radio channels to carry out their jobs.
5. Focus on decentralizing IT architectures
For many tech industry insiders, it might be surprising to discover how extraordinarily monolithic Facebook is in its IT approach. For whatever reason, the company manages its network in a highly centralized way. This approach made the outages worse than they should have been.
It was perhaps a wrong move to put their DNS servers completely within their own network, instead of deploying some in the cloud through an external DNS provider that could be retrieved when the in-house ones could not. In other words, Facebook’s reliance on its own services for the systems managing and protecting its systems compounded the damage.
Another big problem was Facebook’s use of a single management point for all of the company’s resources internationally. With a more decentralized, regional control plane, the apps might have gone offline in one part of the world, but continued working in others. By contrast, AWS and Microsoft Azure use this strategy and Google has, to some extent, moved toward it.
Key Takeaway
Facebook survived the biggest of all outages, and with it, was provided valuable lessons for other businesses to avoid the same fate. The bottom line is if you really must decide between speed and resiliency, think very carefully about what risk you are willing to take and the downside of failure.
If you want your customers, your investors, your regulators, and the broader community to keep confidence in you and assurance you are doing an effective job, you need to be open and honest about what you are doing and why.
Outages due to maintenance errors are not unusual. The key is to secure practices reducing their occurrence and limit the damage caused when they inevitably make our phygital world go dark.